Project 1 -
Penguin Search
Building an interface to identify
and locate penguins in any given image
Check out the code

Introduction
This project was developed to crystalize all that me and my colleagues learned throughout the Data Science Bootcamp from Le Wagon. Our aim was to elaborate a challenging end-to-end project that could amplify the types of problems we would be able to deal with. That’s the reason why we chose the computer vision field and more specifically multiple object detection.
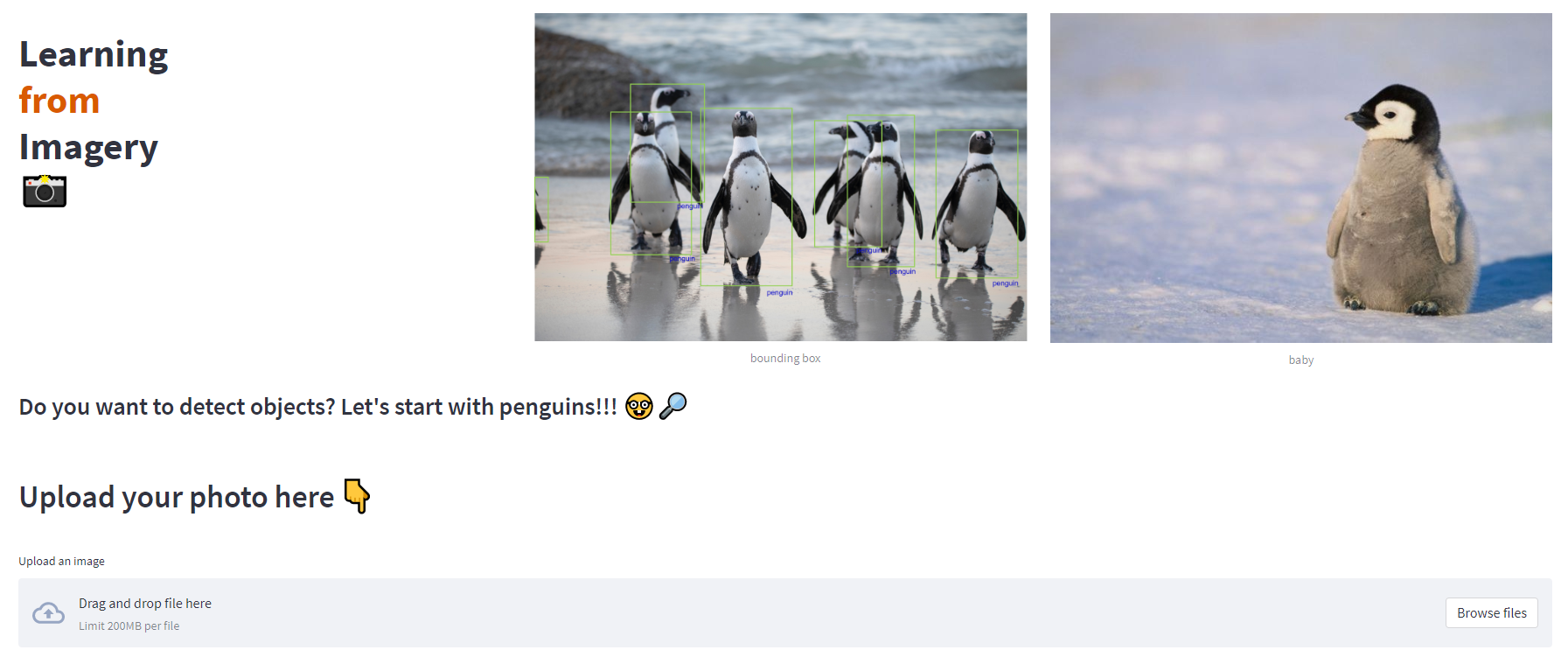
Application
The application is an interface that can be used to identify and locate penguins in any given image. There’s some research that uses that sort of information to analyse the behaviour of a herd not only to assess their health as a group but also as an indicator of how global warming is affecting areas subjected to change in coming years. Therefore this is a first step that can lead to many different uses and applications.
Dataset
The data used came from a 2016 Oxford’s dataset called “Penguin Dataset”. It comprised about 80.000 images taken from cameras placed in several spots in Antarctica with intense flow of penguins or next to their nests. Along with the image set there was another file containing dot annotations from volunteers indicating where the penguins were in each image. There were many images without annotations and a single image might have up to 20 different volunteers marking the spots.

Bounding Boxes
In order to train a supervised model there needs to be an identification of the bounding boxes surrounding the penguins on the training set. Since the dataset provided the dot annotations, the first approach was to use a 30 pixel squared offset from a single volunteer, the one with the most annotations in an image. There are various simplifications implicit in this method since you’re losing the information contained in all the other annotations and the same offset is a bad approximation since the images contain penguins in all sizes, shapes and distances in the images. In this paper some techniques are explored to deal with these problems such as identifying parts of the images that represent the background or foreground, mapping penguin density and annotation densities. All of these are used to map and annotate bounding boxes that better represent the penguins’ locations.
After the first simple approach delivered bad results, we decided to try out a second approach which was to apply an unsupervised model that could differentiate the penguins from the background and return reliable bounding boxes. We used two models both trained with the Resnet 50 dataset: Faster RCNN and Mask-RCNN. The Faster RCNN performed better so it was used to draw the boxes.
Model
The model choice was directed towards dealing with our computational limitations and enough precision to deal with objects showing different sizes and shapes. The chosen strategy was applying transfer-learning using model Faster-RCNN architecture and weights trained from the resnet 50 dataset and then fine-tuned with the penguin dataset so that it would adapt to identifying solely penguins. Our team had very limited resources in terms of processing capacity and time so we had to cut short in terms model tuning. Because of that we only used 5.000 images and didn’t test different hyperparameters to improve model performance.
Production
The application itself was built using Docker to host it online on GCP. The frontend was coded in Streamlit and connected to the backend through an API.
